Optimization is a field of mathematics that focuses on the problem of finding the solution to a minimization problem. More precisely, given a function \(f:\mathbb{R}^{k}\to \mathbb{R}\), we seek \(x^{*}\in\mathcal{C}\subset \mathbb{R}^{k}\) such that \[
f(x^{*}) \leqslant f(x) \text{ for all }x\in\mathcal{C}.
\] The set \(\mathcal{C}\) constraints the solution to leave in a subset of \(\mathbb{R}^{k}\)
When \(\mathcal{C}\) coincides with \(\mathbb{R}^k\) the problem is said to be unconstrained.
In unconstrained optimization, the objective function \(f(x)\) needs to be minimized (or maximized) without any restrictions on the variable \(x\). The problem is described as \[
\min_{x} f(x), \quad x\in\mathbb{R}^k.
\]
Many problems involve constraints that the solution must satisfy, that is, \(\mathcal{C}\) does not coincide with \(\mathbb{R}^k\). For instance, we want to minimize the function over a space where \(x_j < c_j\), \(c_j\in\mathbb{R}\), \(j=1,\ldots,k\) or we may be interested in values of \(x\) that minimizes \(f\) when certain restrictions are satisfied. Generally, the constrained optimization is \[
\begin{aligned}
&\min_{x} \ f(x) \\
&\text{subject to} \\
& \ g_i(x) \leq 0, \quad i = 1, \ldots, m, \\
& \ h_j(x) = 0, \quad j = 1, \ldots, p.
\end{aligned}
\] Here, \(g_i(x)\) and \(h_j(x)\) are functions that represent inequality and equality constraints.
In what follows, we will focus on the class of unconstrained problems where \(f\) is smooth, that is, a function that everywhere continuously differentiable.
A point \(x^*\) is a global minimizer of \(f\) if \(f(x^*)\leqslant f(x)\) for all \(x\) ranging over of of \(\mathbb{R}^k\).
The global minimizer can be difficult to find. The algorithms to solve Equation 1 exploit local knowledge of \(f\), we do not have a clear picture of the overall shape of \(f\) and, as such, we cannot ever be sure that the solution we find is indeed a global solution to the minimization problem. Most algorithms are able to find only a local minimizer, which is a point that achieves the samllest value of \(f\) in a neighborhood.
A point \(x^*\) is a local minimizer if there is a neighborhood1\(\mathcal{N}\) of \(x^*\) such that \(f(x^*)\leqslant f(x)\) for all \(x\in\mathcal{N}\).
A point \(x^*\) is a strict local minimizer if there a neighborhood of \(\mathcal{N}\) such that \(f(x^*) < f(x)\) for all \(x\in \mathcal{N}\).
For instance, for the function \(f(x) = 2024\), every point is a weak local minimizer, while the function \(f(x) = (x-a)^2\) has a strict local minimizer at \(x=a^{-1}\).
Notation: Given a function \(f:\mathbb{R}^k\to\mathbb{R}\), the gradient of \(f\) evaluated at \(x^o\) is: \[
\nabla f(x^o) := \begin{pmatrix}\left.\frac{\partial f(x)}{\partial x_{1}}\right|_{x=x^{o}}\\
\left.\frac{\partial f(x)}{\partial x_{2}}\right|_{x=x^{o}}\\
\vdots\\
\left.\frac{\partial f(x)}{\partial x_{k}}\right|_{x=x^{o}}
\end{pmatrix}.
\] Similarly, the \(k\times k\)hessian matrix of \(f\) evaluated at \(x^o\) is \[
\nabla^{2}f(x^{o})=\begin{pmatrix}\left.\frac{\partial^{2}f(x)}{\partial x_{1}\partial x_{1}}\right|_{x=x^{o}} & \left.\frac{\partial^{2}f(x)}{\partial x_{1}\partial x_{2}}\right|_{x=x^{o}} & \cdots & \left.\frac{\partial^{2}f(x)}{\partial x_{1}\partial x_{k}}\right|_{x=x^{o}}\\
\left.\frac{\partial^{2}f(x)}{\partial x_{2}\partial x_{1}}\right|_{x=x^{o}} & \left.\frac{\partial^{2}f(x)}{\partial x_{2}\partial x_{2}}\right|_{x=x^{o}} & \cdots & \left.\frac{\partial^{2}f(x)}{\partial x_{2}\partial x_{k}}\right|_{x=x^{o}}\\
\vdots & \vdots & & \vdots\\
\left.\frac{\partial^{2}f(x)}{\partial x_{k}\partial x_{1}}\right|_{x=x^{o}} & \left.\frac{\partial^{2}f(x)}{\partial x_{k}\partial x_{2}}\right|_{x=x^{o}} & \cdots & \left.\frac{\partial^{2}f(x)}{\partial x_{k}\partial x_{k}}\right|_{x=x^{o}}
\end{pmatrix}.
\]
Fundamental mathematical tools
The fundamental mathematical tool used to study minimizers of smooth functions is Taylor’s theorem.
Theorem 1 Suppose that \(f:\mathbb{R}^k\to\mathbb{R}\) is continuously differentiable and that \(p\io\mathbb{R}^k\). Then we have that \[
f(x+p) = f(x) + \nabla f(x+tp)'p,
\] for some \(t\in(0,1)\). Moreover, if \(f\) is twice continuously differentiable, we have that \[
\nabla f(x+tp) = \nabla f(x) + \int_{0}^{1} \nabla^2 f(x+tp)p\,dt,
\] and that \[
f(x+p) = f(x)+\nabla f(x)'p + \frac{1}{2}p'\nabla^2 f(x+tp)p.
\]
The necessary conditions for optimality are derived assuming that \(x^*\) is a local minimizer and the proving facts about \(\nabla f(x^*)\) and \(\nabla^2 f(x^*)\).
Theorem 2 If \(x^*\) is a local optimizer and \(f\) is continuously differentiable in an open neighborhood of \(x^*\), then \(\nabla f(x^*)=0\) (first-order necessary condition); if \(\nabla^2 f\) exists and its continuous in an open neighborhood of \(x^*\), then \(\nabla^2 f(x^*)\) is positive definite (second-order necessary conditions).2
Sufficient conditions for optimality are conditions on the derivatives of \(f\) at the point \(x^*\) that guarantee that \(x^*\) is a local minimizer.
Theorem 3 Suppose that \(\nabla^2 f(x^*)\) is continuous in an open neighborhood of \(x^*\) and that \(\nabla f(x^*)=0\) and \(\nabla^2 f(x^*)\) is positive definite. Then \(x^*\) is a strict local minimizer of \(f\).
The second-order sufficient conditions guarantee something stronger than the necessary conditions; namely, that the minimizer is a strict local minimizer. Note too that the second-order sufficient conditions are not necessary: a point \(x^∗\) may be a strict local minimizer, and yet may fail to satisfy the sufficient conditions. A simple example is given by the function \(f(x) = x^3\), for which the point \(x^∗=0\) is a strict local minimizer at which the Hessian matrix vanishes (and is therefore not positive definite).
When the objective function is convex, local and global minimizers are simple to characterize.
Theorem 4 When \(f\) is convex, any local minimizer of \(x^*\) is a global minimizer of \(f\). If in addition, \(f\) is differentiable, any stationary point \(x^*\) is a global minimizer.
Overview of algorithms
A common approach to optimization is to incrementally improve a point \(x\) by taking a step that minimizes the objective value based on a local model. The local model may be obtained, for example, from a first- or second-order Taylor approximation. Optimization algorithms that follow this general approach are referred to as descent direction methods. They start with a design point \(x^{(0)}\) and then generate a sequence of points, sometimes called iterates, to converge to a local minimum.
import numpy as npimport matplotlib.pyplot as plt# Define the function and its derivativedef f(x):return x**2- np.log(x)def df(x):return2*x -1/xdef connectpoints(x,y,p1,p2): x1, x2 = x[p1], x[p2] y1, y2 = y[p1], y[p2] plt.plot([x1,x2],[y1,y2],'k-')# Initial pointx0 =2alpha =0.3# Gradient descent updatex1 = x0 - alpha * df(x0)x2 = x1 - alpha * df(x1)# Points for the function plotx = np.linspace(-2.5, 2.5, 400)y = f(x)# Tangent line at x0 (y = m*x + b)# Creating the plotplt.figure(figsize=(8, 5))plt.plot(x, y, label='f(x) = x^2')plt.scatter([x0, x1], [f(x0), f(x1)], color='red') # Pointsm = df(x0)b = f(x0) - m*x0tangent_line = m*x + bplt.plot(x, tangent_line, 'b--', label=f'Tangent at x0={x0}')plt.arrow(x0, 0.4, x1-x0, 0.0, head_width=0.1, length_includes_head=True, color ='r')m = df(x1)b = f(x1) - m*x1tangent_line = m*x + bplt.plot(x, tangent_line, 'b--', label=f'Tangent at x0={x1}', )plt.ylim([-0.2,6])plt.xlim([-0.4,3])plt.plot(x, tangent_line, 'b--', label=f'Tangent at x0={x1}', )m = df(x0)b = f(x0) - m*x0tangent_line = m*x + bplt.scatter(x0, f(x0), color='green') # Initial pointplt.scatter(x1, f(x1), color='green') # Next point after stepplt.scatter(x2, f(x2), color='green') # Next point after stepplt.arrow(x1, 0., x2-x1, 0., head_width=0.1, length_includes_head=True, color ='r')plt.title('Gradient Descent on f(x)')plt.xlabel('x')plt.ylabel('f(x)')plt.xticks([]) # Remove x-axis ticksplt.xticks([x0, x1, x2], [r"$x^{(0)}$", r"$x^{(1)}$", r"$x^{(2)}$"])#plt.legend()plt.grid(True)plt.plot([x0, x0],[f(x0), 0],'g--')plt.plot([x1, x1],[f(x1), 0],'g--')plt.plot([x2, x2],[f(x1), 0],'g--')plt.show()
/var/folders/cc/94_qfp2s31zbxp0zcs5tn2wr0000gn/T/ipykernel_96888/189701708.py:6: RuntimeWarning: invalid value encountered in log
return x**2 - np.log(x)
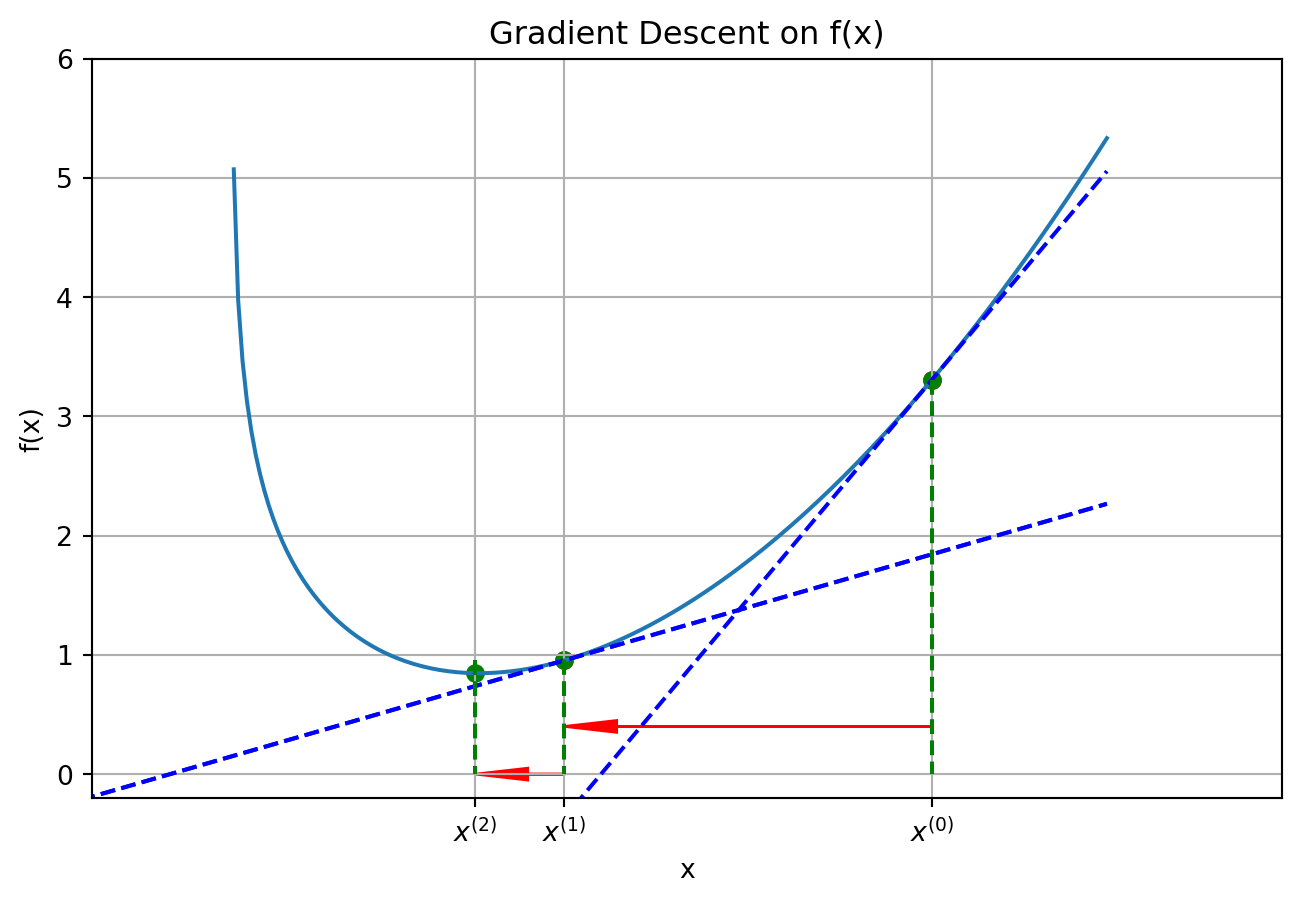
Figure 1: Gradient descent
The intuition behind this approach is relatively simple. Consider the function plotted in Figure 1. We start the algorithm at \(x^{(0)}\). The derivative at this point (the tangent line in blue) is positive, that is, \(f'(x^{(0)})>0\). Thus, to descend toward smaller values of the function have to set a point \(x^{(1)}\) smaller. One possibility is to use the following iteration \[
x^{(1)} = x^{(0)} - \alpha \nabla f(x^{(0)}),
\] where \(\alpha\in(0,1)\) is the step size. As it can be seen from Figure 1, at this point the value of \(f\) is now lower. Applying a new iterate we obtain \(x^{(2)} = x^{(1)} - \alpha f'(x^{(1)})\) which is now very close to the minimum value of the function.
We will keep iterating until the termination condition is satisfied. The termination condition will be satisfied when the current iterate is likely to be a local minimum.[^termination]
3: The most common termination conditions are 1. Maximum iterations. We may want to terminate when the number of iterations \(k\) exceeds some threshold \(k_max\). Alternatively, we might want to terminate once a maximum amount of elapsed time is exceeded. 2. Absolute improvement. This termination condition looks at the change in the function value over subsequent steps. If the change is smaller than a given threshold, it will terminate: \[
f(x^{(k)}) - f(x^{(r+1)}) < \epsilon_a
\] 1. Relative improvement. This termination condition looks at the change in function value but uses the relative change of the function. The iterations will terminate if \[
f(x^{(k)}) - f(x^{(r+1)}) < \epsilon_r|f(x^{(k)})|
\] 1. Gradient magnitude. We can terminate if the derivative is smaller than a certain tolerance \[
\Vert \delta f(x^{(k)}) \Vert < \epsilon_g
\]
The same logic can be applied to the case in which \(f:\mathbb{R}^k \to \mathbb{R}\) the only difference is that now \(\nabla f(x^{(0)})\) is a \(k\times 1\) vector instead of being a scalar.
The gradient descent idea can be generalized by considering the following iterate \[
x^{(r)} = x^{(r-1)} - \alpha d^{(r)},
\] where \(d^{(r)}\) is a descent direction. The idea of this generalization is that instead of using the gradient as direction, we can use different directions that might speed up the algorithm.
When \(d^{(r)} = \nabla f(x^{(r)})\), the algorithm is called the gradient descent (and direction is called the direction of deepest descent).
Directions that can be used belong to two classes: 1. first-order: the direction only uses information about the gradient of \(f\). The many variations of the gradient descent (Ada, Momentum, etc.) and the conjugate gradient method belong to this class. 2. second order: the direction incorporate information about the second derivatives of \(f\). The key idea here is that \[
f(x^{(r+1)}) = f(x^{(r)}) + \nabla f'(x^{(r)})(x^{(r+1)}-x^{(r)}) + (x^{(r+1)}-x^{(r)}) \dot{H}_k (x^{(r+1)}-x^{(r)}),
\] where \(\dot{H}_k = \nabla^2 f(\dot{x}^{(r)})\) is the Hessian evaluated at some point between \(x^{(r+1)}\) and \(x^{(r)}\). Then, approximating the gradient of \(f\) and setting it equal to zero yields \[
x^{(r+1)} = x^{(r)}-[\nabla^2 f(x^{(r)})]^{-1} \nabla f(x^{(r)}) +
\] which suggests using the inverse of the hessian to form the direction. Since evaluating the Hessian at each iterate is too costly computationally, different algorithms approximate the Hessian in different ways.
A simple implementation of gradient descent
The following code implements a gradient descent with steepest direction in Python.
from numpy import linalg as ladef steepest_descent(f, gradient, initial_guess, learning_rate, num_iterations =100, epsilon_g =1e-07): x = initial_guessfor i inrange(num_iterations): grad = gradient(x) x = x - learning_rate * grad normg = la.norm(grad)print(f"Iteration {i+1}: x = {x}, f(x) = {f(x)}, ||g(x)||={normg}")## Termination conditionif normg < epsilon_g:breakreturn x
This is the Julia version.
using LinearAlgebra ## needed for norm
function steepest_descent(f, gradient, initial_guess, learning_rate; num_iterations = 100; epsilon_g = 1e-7)
x = initial_guess
for i in 1:num_iterations
grad = gradient(x)
x = x - learning_rate * grad
normg = norm(g)
println("Iteration $i: x = $x, f(x) = $(objective_function(x)), ||g(x)||=$(normg)")
if normg < epsilon_g
break
end
end
return x
end
Suppose we want to solve the following problem \[
\min_{x} f(x)
\] where, for some \(d>1\), \[
f(x) = \sum_{i=1}^d \left((x_i-3)^2 \right)
\] The gradient of this function is \[
\nabla f(x)=\begin{pmatrix}2(x_{1}-3)\\
2(x_{2}-3)\\
\vdots\\
2(x_{d}-3)
\end{pmatrix}.
\]
Iteration 1: x = [1.2 1.2], f(x) = 6.479999999999999, ||g(x)||=8.48528137423857
Iteration 2: x = [1.92 1.92], f(x) = 2.3327999999999993, ||g(x)||=5.091168824543142
Iteration 3: x = [2.352 2.352], f(x) = 0.8398079999999992, ||g(x)||=3.0547012947258847
Iteration 4: x = [2.6112 2.6112], f(x) = 0.3023308799999997, ||g(x)||=1.8328207768355302
Iteration 5: x = [2.76672 2.76672], f(x) = 0.10883911679999973, ||g(x)||=1.099692466101318
Iteration 6: x = [2.860032 2.860032], f(x) = 0.039182082047999806, ||g(x)||=0.6598154796607905
Iteration 7: x = [2.9160192 2.9160192], f(x) = 0.014105549537279988, ||g(x)||=0.39588928779647375
Iteration 8: x = [2.94961152 2.94961152], f(x) = 0.005077997833420814, ||g(x)||=0.23753357267788475
Iteration 9: x = [2.96976691 2.96976691], f(x) = 0.0018280792200315037, ||g(x)||=0.1425201436067311
Iteration 10: x = [2.98186015 2.98186015], f(x) = 0.0006581085192113414, ||g(x)||=0.08551208616403891
Iteration 11: x = [2.98911609 2.98911609], f(x) = 0.00023691906691608675, ||g(x)||=0.051307251698423345
Iteration 12: x = [2.99346965 2.99346965], f(x) = 8.529086408979587e-05, ||g(x)||=0.03078435101905426
Iteration 13: x = [2.99608179 2.99608179], f(x) = 3.070471107232651e-05, ||g(x)||=0.01847061061143306
Iteration 14: x = [2.99764908 2.99764908], f(x) = 1.1053695986035874e-05, ||g(x)||=0.011082366366859834
Iteration 15: x = [2.99858945 2.99858945], f(x) = 3.9793305549719125e-06, ||g(x)||=0.0066494198201153985
Iteration 16: x = [2.99915367 2.99915367], f(x) = 1.4325589997895879e-06, ||g(x)||=0.003989651892068737
Iteration 17: x = [2.9994922 2.9994922], f(x) = 5.15721239924432e-07, ||g(x)||=0.002393791135240991
Iteration 18: x = [2.99969532 2.99969532], f(x) = 1.8565964637257903e-07, ||g(x)||=0.0014362746811448456
Iteration 19: x = [2.99981719 2.99981719], f(x) = 6.683747269425835e-08, ||g(x)||=0.000861764808686405
Iteration 20: x = [2.99989032 2.99989032], f(x) = 2.4061490169894037e-08, ||g(x)||=0.0005170588852123454
Iteration 21: x = [2.99993419 2.99993419], f(x) = 8.662136461115092e-09, ||g(x)||=0.00031023533112715604
Iteration 22: x = [2.99996051 2.99996051], f(x) = 3.118369125973376e-09, ||g(x)||=0.0001861411986757912
Iteration 23: x = [2.99997631 2.99997631], f(x) = 1.1226128853672496e-09, ||g(x)||=0.00011168471920497228
Iteration 24: x = [2.99998578 2.99998578], f(x) = 4.0414063872210937e-10, ||g(x)||=6.70108315234858e-05
Iteration 25: x = [2.99999147 2.99999147], f(x) = 1.454906299338991e-10, ||g(x)||=4.020649891358905e-05
Iteration 26: x = [2.99999488 2.99999488], f(x) = 5.237662677983984e-11, ||g(x)||=2.4123899347651e-05
Iteration 27: x = [2.99999693 2.99999693], f(x) = 1.8855585639651492e-11, ||g(x)||=1.447433960909303e-05
Iteration 28: x = [2.99999816 2.99999816], f(x) = 6.788010829620027e-12, ||g(x)||=8.684603765204602e-06
Iteration 29: x = [2.99999889 2.99999889], f(x) = 2.4436838986632097e-12, ||g(x)||=5.210762258871547e-06
Iteration 30: x = [2.99999934 2.99999934], f(x) = 8.797262039900029e-13, ||g(x)||=3.1264573553229284e-06
Iteration 31: x = [2.9999996 2.9999996], f(x) = 3.167014331536526e-13, ||g(x)||=1.8758744136961865e-06
Iteration 32: x = [2.99999976 2.99999976], f(x) = 1.1401251593531493e-13, ||g(x)||=1.1255246477152823e-06
Iteration 33: x = [2.99999986 2.99999986], f(x) = 4.10445057876081e-14, ||g(x)||=6.753147886291694e-07
Iteration 34: x = [2.99999991 2.99999991], f(x) = 1.477602202246525e-14, ||g(x)||=4.0518887342871644e-07
Iteration 35: x = [2.99999995 2.99999995], f(x) = 5.31936792808749e-15, ||g(x)||=2.431133235548003e-07
Iteration 36: x = [2.99999997 2.99999997], f(x) = 1.914972432124978e-15, ||g(x)||=1.4586799413288017e-07
Iteration 37: x = [2.99999998 2.99999998], f(x) = 6.893900623730809e-16, ||g(x)||=8.752079597729852e-08
array([2.99999998, 2.99999998])
function f(x)
sum((x.-3.0).^2)
end
function gradient(x)
2.*(x.-3.0)
end
steepest_descent(f, gradient, [.0, .0], 0.2)
Calculating the derivative
When the gradient is difficult to calculate analytically, we can use algorithmically calculate the derivative of the function \(f\).
Finite difference: We use \[
\lim_{h} \frac{f(x+h) - f(x)}{h}
\]
using FiniteDifferences
# Create a central finite difference method with the default settings
fdm = central_fdm(5, 1)
# Calculate the gradient at a point
x0 = [1.0, 2.0]
gradient = grad(fdm, f, x0)
println("Numerical Gradient:", gradient)
import numpy as npfrom scipy.optimize import approx_fprimeepsilon = np.sqrt(np.finfo(float).eps) # Point at which to calculate the gradientx0 = np.array([1.0, 2.0])# Calculate the gradient at the point x0gradient = approx_fprime(x0, f, epsilon)print("Gradient at x0:", gradient)
Gradient at x0: [-4. -2.]
Automatic differentiation
Automatic Differentiation (AD) is a computational technique used to evaluate the derivative of a function specified by a computer program. AD exploits the fact that any computer program, no matter how complex, executes a sequence of elementary arithmetic operations and functions (like additions, multiplications, and trigonometric functions). By applying the chain rule to these operations, AD efficiently computes derivatives of arbitrary order, which are accurate up to machine precision. This contrasts with numerical differentiation, which can introduce significant rounding errors.
One popular Python library that implements automatic differentiation is autograd. It extends the capabilities of NumPy by allowing you to automatically compute derivatives of functions composed of many standard mathematical operations. Here is a simple example of using autograd to compute the derivative of a function:
Now, let’s compute the derivative of the function defined above.
import autograd.numpy as np # Import wrapped NumPyfrom autograd import grad # Import the gradient function# Create a function that returns the derivative of fdf = grad(f)# Evaluate the derivative at x = piprint("The derivative of f(x) at x = [0.2, 0.1] is:", df(np.array([0.2, 0.1])))
The derivative of f(x) at x = [0.2, 0.1] is: [-5.6 -5.8]
When comparing the precision and applicability of finite difference methods and automatic differentiation (AD), especially for functions with large input dimensions, there are several key points to consider.
Finite difference methods approximate derivatives by evaluating differences in function values at nearby points. The accuracy of these methods is highly dependent on the step size chosen: too large, and the approximation becomes poor; too small, and floating-point errors can dominate the result. This trade-off can be particularly challenging in high-dimensional spaces as errors can accumulate more significantly (each partial derivative may introduce errors that affect the overall gradient computation).
AD computes derivatives using the exact chain rule and is not based on numerical approximations of difference quotients. Therefore, it can provide derivatives that are accurate to machine precision. AD efficiently handles computations in high dimensions because it systematically applies elementary operations and chain rules, bypassing the curse of dimensionality that often affects finite difference methods. AD is less sensitive to the numerical issues that affect finite differences, such as choosing a step size or dealing with subtractive cancellation.
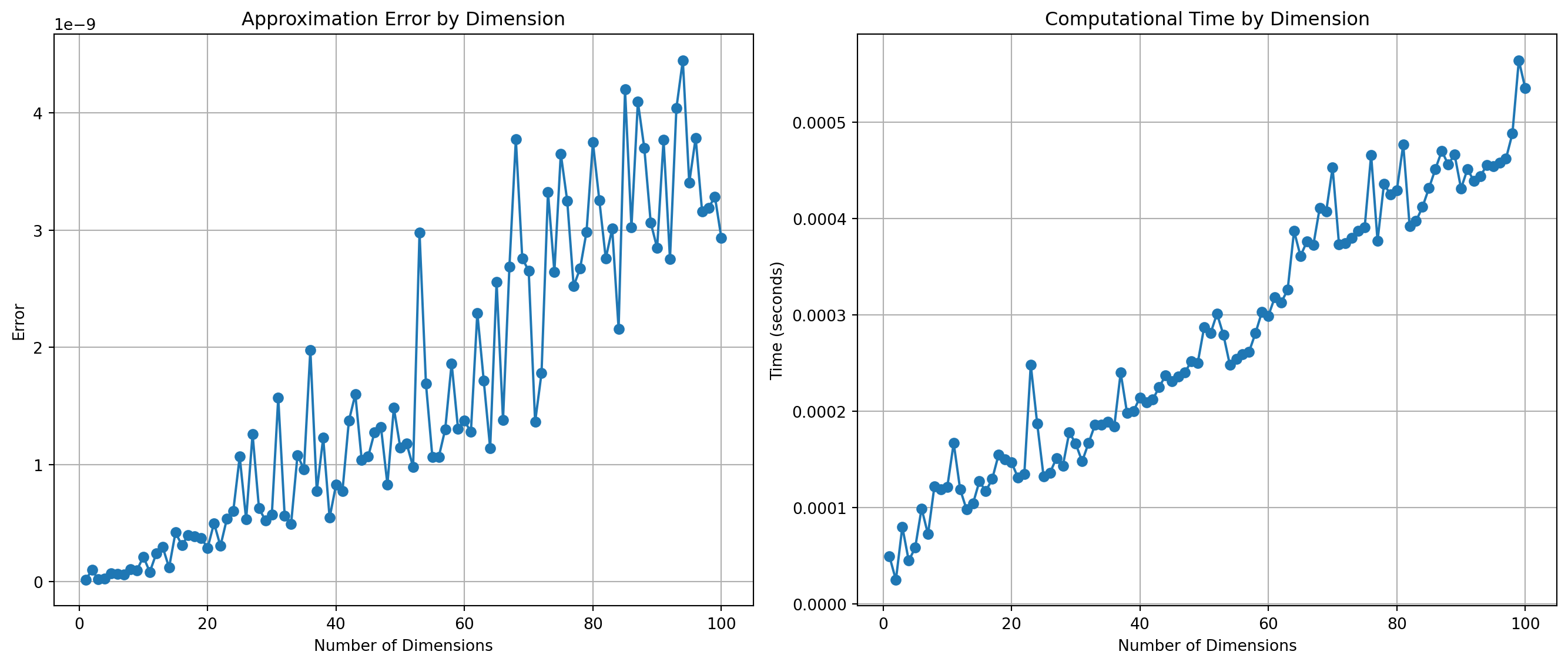
The visualization provided by @fig-error demonstrates the comparative performance of the finite difference method and automatic differentiation (AD) when used to calculate gradients. This graph illustrates a key observation: as the dimensionality of the input increases, the error associated with the finite difference method tends to rise almost linearly. This escalation in error is accompanied by an increase in computation time, underscoring the method’s sensitivity to higher dimensions.
In contrast, the automatic differentiation method showcases remarkable stability across dimensions. The error remains negligible, essentially zero, highlighting AD’s inherent precision. Furthermore, AD’s computation time remains consistent regardless of input dimensionality. This performance characteristic of AD is due to its methodological approach, which systematically applies the chain rule to derive exact derivatives, bypassing the numerical instability and scaling issues often encountered with finite differences.
These insights are particularly relevant in fields that rely heavily on precise and efficient computation of derivatives, such as in numerical optimization, machine learning model training, and dynamic systems simulation. The stability and scalability of AD make it an invaluable tool in these areas, especially when dealing with high-dimensional data sets or complex models.
import numpy as npimport matplotlib.pyplot as pltimport timedef multivariate_function(x):""" A sample multivariate function, sum of squares plus sin of each component. """return np.sum(x**2+ np.sin(x))def analytical_derivative(x):""" Analytical derivative of the multivariate function. """return2*x + np.cos(x)def finite_difference_derivative(f, x, h=1e-5):""" Compute the gradient of `f` at `x` using the central finite difference method. """ grad = np.zeros_like(x)for i inrange(len(x)): x_plus = np.copy(x) x_minus = np.copy(x) x_plus[i] += h x_minus[i] -= h grad[i] = (f(x_plus) - f(x_minus)) / (2*h)return grad# Range of dimensionsdimensions =range(1, 101)errors = []times = []# Loop over dimensionsfor dim in dimensions: x = np.random.randn(dim)# Analytical derivative true_grad = analytical_derivative(x)# Start timing start_time = time.time()# Finite difference derivative fd_grad = finite_difference_derivative(multivariate_function, x)# End timing elapsed_time = time.time() - start_time times.append(elapsed_time)# Error error = np.linalg.norm(fd_grad - true_grad) errors.append(error)# Plotting errorplt.figure(figsize=(14, 6))plt.subplot(1, 2, 1)plt.plot(dimensions, errors, marker='o')plt.xlabel('Number of Dimensions')plt.ylabel('Error')plt.title('Approximation Error by Dimension')plt.grid(True)# Plotting computational timeplt.subplot(1, 2, 2)plt.plot(dimensions, times, marker='o')plt.xlabel('Number of Dimensions')plt.ylabel('Time (seconds)')plt.title('Computational Time by Dimension')plt.grid(True)plt.tight_layout()plt.show()
Figure 2
Using solver
It is almost always advantageous to utilize established minimization routines and libraries rather than crafting custom code from scratch. This approach not only saves time but also leverages the extensive testing and optimizations embedded within these libraries, which are designed to handle a broad range of mathematical challenges efficiently and accurately.
In Python, the scipy.optimize module from the SciPy library is a robust toolkit that provides several algorithms for function minimization, including methods for unconstrained and constrained optimization. Some of the notable algorithms include BFGS, Nelder-Mead, and conjugate gradient, among others. These algorithms are well-suited for numerical optimization in scientific computing.
In Julia, Optim.jl offers a similar breadth of optimization routines, with support for a variety of optimization problems, from simple univariate function minimization to complex multivariate cases. Optim.jl includes algorithms like L-BFGS, Gradient Descent, and Newton’s Method, each tailored for specific types of optimization scenarios.
Both Python’s SciPy and Julia’s Optim.jl represent just a slice of the available tools. There are many other solvers and libraries dedicated to optimization. The most widely used is Ipopt which is particularly useful for problems that require embedding in lower-level systems for performance.
The choice of a solver can depend on several factors:
Problem Type: Some solvers are better suited for large-scale problems, others for problems with complex constraints, or for nondifferentiable or noisy functions.
Accuracy and Precision: Different algorithms and implementations can provide varying levels of precision and robustness, important in applications like aerospace or finance.
Performance and Speed: Depending on the implementation, some solvers might be optimized for speed using advanced techniques like parallel processing or tailored data structures.
Ease of Use and Flexibility: Some libraries offer more user-friendly interfaces and better documentation, which can be crucial for less experienced users or complex projects where customization is key.
Julia’s Optim.jl
Optim.jl supports various optimization algorithms. For our simple example, we can use the BFGS method, which is suitable for smooth functions and is part of a family of quasi-Newton methods.
You can now call the optimize function from Optim.jl, specifying the function, an initial guess, and the optimization method. Here is how you do it:
# Initial guess
initial_guess = [0.0, 0.0]
# Perform the optimization
result = optimize(f, initial_guess, BFGS())
The result object contains all the information about the optimization process, including the optimal values found, the value of the function at the optimum, and the convergence status:
If your function is more complex or if you want to speed up the convergence for large-scale problems, you can also provide the gradient (and even the Hessian) to the optimizer. Optim.jl can utilize these for more efficient calculations.
For constrained optimization, Optim.jl has support for simple box constraints which can be set using the Fminbox method to wrap around other methods like BFGS.
# Define the bounds
lower_bounds = [0.5, 1.5]
upper_bounds = [1.5, 2.5]
# Initial guess within the bounds
initial_guess = [1.0, 2.0]
# Set up the optimizer with Fminbox
optimizer = Fminbox(BFGS())
# Run the optimization with bounds
result = optimize(f, lower_bounds, upper_bounds, initial_guess, optimizer, Optim.Options(g_tol = 1e-6))
Python’s minimize
The scipy.optimize.minimize function in Python is a versatile solver for minimization problems of both unconstrained and constrained functions. It provides a wide range of algorithms for different kinds of optimization problems.
SciPy’s minimize function supports various methods like ‘BFGS’, ‘Nelder-Mead’, ‘TNC’, etc. The choice of method can depend on the nature of your problem (e.g., whether it has constraints, whether the function is differentiable, etc.). As in the Julia’s discussion, we’ll use ‘BFGS’.
Implement the likelihood function for an AR(7) model in Python. You are required to code both the conditional and unconditional likelihood functions.
Conditional Likelihood: This approach uses the first 7 observations as given and starts the likelihood calculation from the 8th observation.
Unconditional Likelihood: This approach integrates over the initial conditions (first 7 observations) using their theoretical or estimated distribution.
Use the following model specification for the AR(7) process: \[
y_t = \phi_0 + \phi_1 y_{t-1} + \phi_2 y_{t-2} + \dots + \phi_7 y_{t-7} + \epsilon_t
\] where \(\epsilon_t\) is i.i.d. normal with mean zero and variance \(\sigma^2\).
Maximizing the Likelihood
Write Python, Julia or R code to maximize the likelihood functions (both conditional and unconditional) with respect to the parameters \(\phi_0, \phi_1, \dots, \phi_7,\) and \(\sigma^2\). You may consider using optimization routines available in libraries such as scipy.optimize or Optim.jl.
Parameter Estimation
Estimate the parameters of the AR(7) model using both conditional and unconditional likelihood approaches. Utilize the monthly log differences of INDPRO from the FRED-MD dataset for this purpose.
You will need to preprocess the data to calculate log differences.
Forecasting
With the estimated parameters from both approaches, forecast the future values of the log differences of INDPRO for the next 8 months (\(h=1,2,\dots,8\)).
(Optional) Provide a brief comparison of the forecast accuracy from both sets of parameters based on out-of-sample forecasting. Discuss any notable differences and potential reasons for these differences.
Deliverables: - A Python script containing the implementations and results for the tasks outlined above. - A report discussing the methodology, results, and insights from the forecasting comparison. Include visualizations of the forecast against actual data if available.
Assessment Criteria: - Correctness and efficiency of the likelihood function implementations. - Accuracy and robustness of the optimization procedure. - Clarity and depth of the analysis in the report, especially in discussing the different outcomes from the conditional and unconditional methods. - Quality of the code, including readability and proper documentation.
Resources: - FRED-MD dataset: Access the dataset directly from the FRED website or through any API that provides access to it. - SciPy library documentation for optimization functions. - Optim.jl
This assignment will test your ability to implement statistical models, manipulate time-series data, perform parameter estimation, and use statistical methods to forecast future values.
The AR(7) likelihood
The AR(7) process is given by the equation: \[
X_t = c + \phi_1 X_{t-1} + \phi_2 X_{t-2} + \ldots + \phi_7 X_{t-7} + \epsilon_t
\] where \(\epsilon_t\) is white noise with mean zero and variance \(\sigma^2\), and \(c\) is a constant.
This AR(7) process can be rewritten in a matrix form that resembles an AR(1) process by defining a vector \(\mathbf{Z}_t\) that includes lags of the process up to \(X_{t-6}\)\[
\mathbf{Z}_t = A\mathbf{Z}_{t-1} + \mathbf{u}_t.
\] The state vector \(\mathbf{Z}_t\), the companion matrix \(\mathbf{A}\), and \(\mathbf{u}_t\) are: \[
\mathbf{Z}_t = \begin{bmatrix}
X_t \\
X_{t-1} \\
X_{t-2} \\
X_{t-3} \\
X_{t-4} \\
X_{t-5} \\
X_{t-6}
\end{bmatrix}, \quad
\mathbf{A} = \begin{bmatrix}
\phi_1 & \phi_2 & \phi_3 & \phi_4 & \phi_5 & \phi_6 & \phi_7 \\
1 & 0 & 0 & 0 & 0 & 0 & 0 \\
0 & 1 & 0 & 0 & 0 & 0 & 0 \\
0 & 0 & 1 & 0 & 0 & 0 & 0 \\
0 & 0 & 0 & 1 & 0 & 0 & 0 \\
0 & 0 & 0 & 0 & 1 & 0 & 0 \\
0 & 0 & 0 & 0 & 0 & 1 & 0
\end{bmatrix}, \quad
\mathbf{u}_t = \begin{pmatrix}
\varepsilon_t \\
0 \\
\vdots\\
0
\end{pmatrix}
\]
The process is stationary if the eigenvalues of \(A\) are all inside the unit circle, that is, they are all less than one in absolute value.
If the process is stationary, the mean \(\mathbf{\mu}\) of the vector \(\mathbf{Z}_t\) satisfies: \[
\mathbf{\mu} = \mathbf{A} \mathbf{\mu} + \mathbf{b}
\] where \(\mathbf{b}\) is a column vector with \(c\) in the first row and zeros elsewhere. Solving for \(\mathbf{\mu}\) yields: \[
\mathbf{\mu} = (I - \mathbf{A})^{-1} \mathbf{b}.
\]
The variance-covariance matrix \(\Sigma\) of \(\mathbf{Z}_t\) satisfies the equation: \[
\Sigma = \mathbf{A} \Sigma \mathbf{A}^T + \mathbf{Q}
\tag{2}\]
where \(\mathbf{Q} = E\mathbf{u}_t\mathbf{u}'_t\) is a matrix with \(\sigma^2\) in the top-left corner and zeros elsewhere.
Equation 2 is called the discrete Lyapunov equation and solving it for \(\Sigma\) typically involves using iterative or analytical methods.
import numpy as npimport scipy def unconditional_ar_mean_variance(c, phis, sigma2):## The length of phis is p p =len(phis) A = np.zeros((p, p)) A[0, :] = phis A[1:, 0:(p-1)] = np.eye(p-1)## Check for stationarity eigA = np.linalg.eig(A)ifall(np.abs(eigA.eigenvalues)<1): stationary =Trueelse: stationary =False# Create the vector b b = np.zeros((p, 1)) b[0, 0] = c# Compute the mean using matrix algebra I = np.eye(p) mu = np.linalg.inv(I - A) @ b# Solve the discrete Lyapunov equation Q = np.zeros((p, p)) Q[0, 0] = sigma2#Sigma = np.linalg.solve(I - np.kron(A, A), Q.flatten()).reshape(7, 7) Sigma = scipy.linalg.solve_discrete_lyapunov(A, Q)return mu.ravel(), Sigma, stationary# Example usage:phis = [0.2, -0.1, 0.05, -0.05, 0.02, -0.02, 0.01]c =0sigma2 =0.5mu, Sigma, stationary = unconditional_ar_mean_variance(c, phis, sigma2)print("The process is stationary:", stationary)print("Mean vector (mu):", mu)print("Variance-covariance matrix (Sigma);", Sigma)
The function unconditional_ar_mean_variance returns the expected value and the variance of the unconditional distribution of \((y_t, \dots, y_{t-p})\). It also returns stationary that is True if the process with parameters phi is stationary.
You can use this function to calculate the unconditional loglikelihood.
We start by writing a function that calculates the conditional likelihood
from scipy.stats import normfrom scipy.stats import multivariate_normalimport numpy as npdef lagged_matrix(Y, max_lag=7): n =len(Y) lagged_matrix = np.full((n, max_lag), np.nan) # Fill each column with the appropriately lagged datafor lag inrange(1, max_lag +1): lagged_matrix[lag:, lag -1] = Y[:-lag]return lagged_matrixdef cond_loglikelihood_ar7(params, y): c = params[0] phi = params[1:8] sigma2 = params[8] mu, Sigma, stationary = unconditional_ar_mean_variance(c, phi, sigma2)## We could check that at phis the process is stationary and return -Inf if it is notifnot(stationary):return-np.inf## The distribution of # y_t|y_{t-1}, ..., y_{t-7} ~ N(c+\phi_{1}*y_{t-1}+...+\phi_{7}y_{t-7}, sigma2)## Create lagged matrix X = lagged_matrix(y, 7) yf = y[7:] Xf = X[7:,:] loglik = np.sum(norm.logpdf(yf, loc=(c + Xf@phi), scale=np.sqrt(sigma2)))return loglikdef uncond_loglikelihood_ar7(params, y):## The unconditional loglikelihood## is the unconditional "plus" the density of the## first p (7 in our case) observations cloglik = cond_loglikelihood_ar7(params, y)## Calculate initial# y_1, ..., y_7 ~ N(mu, sigma_y) c = params[0] phi = params[1:8] sigma2 = params[8] mu, Sigma, stationary = unconditional_ar_mean_variance(c, phi, sigma2)ifnot(stationary):return-np.inf mvn = multivariate_normal(mean=mu, cov=Sigma, allow_singular=True) uloglik = cloglik + mvn.logpdf(y[0:7])return uloglik## Exampleparams = np.array([0.0, ## c0.2, -0.1, 0.05, -0.05, 0.02, -0.02, 0.01, ## phi1.0## sigma2 ])## Fake datay = np.random.normal(size=100)## The conditional distributioncond_loglikelihood_ar7(params, y)## The unconditional distributionuncond_loglikelihood_ar7(params, y)
-140.60674266702924
You can now feed these functions to minimize to obtain the maximum likelihood parameters.
## Unconditional - define the negative loglikelihood## Starting value. ## These estimates should be close to the OLSX = lagged_matrix(y, 7)yf = y[7:]Xf = np.hstack((np.ones((93,1)), X[7:,:]))beta = np.linalg.solve(Xf.T@Xf, Xf.T@yf)sigma2_hat = np.mean((yf - Xf@beta)**2)params = np.hstack((beta, sigma2_hat))def cobj(params, y): return- cond_loglikelihood_ar7(params,y)results = scipy.optimize.minimize(cobj, params, args = y, method='L-BFGS-B')## If everything is correct, results.x should be equal to the OLS parameters.## Not the conditionaldef uobj(params, y): return- uncond_loglikelihood_ar7(params,y)bounds_constant =tuple((-np.inf, np.inf) for _ inrange(1))bounds_phi =tuple((-1, 1) for _ inrange(7))bounds_sigma =tuple((0,np.inf) for _ inrange(1))bounds = bounds_constant + bounds_phi + bounds_sigma## L-BFGS-B support boundsresults = scipy.optimize.minimize(uobj, results.x, args = y, method='L-BFGS-B', bounds = bounds)
Footnotes
A neighborhood of a point \(x\in\mathbb{R}\) is any open subset of \(\mathbb{R}^k\) containing \(x\).↩︎
A square matrix \(H\) is positive definite if for every \(z\in\mathbb{R}^k\) with \(\Vert z \Vert\neq 0\), \(z'Hz>0\).↩︎