This assignment introduces students to practical and theoretical aspects of macroeconometrics, focusing on forecasting using the FRED-MD dataset. Students will learn to handle macroeconomic data, perform necessary transformations, apply univariate models to predict key economic indicators and to evaluate these forecasts.
The FRED-MD dataset
The FRED-MD dataset is a comprehensive monthly database for macroeconomic research compiled by the Federal Reserve Bank of St. Louis. It features a wide array of economic indicators. The list of economic indicators can be obtained from the paper accompanying the data pdf.
The data can be downloaded here. The page contains all the different vintages of the data.
Let us start to download the current.csv file:
import pandas as pd# Load the datasetdf = pd.read_csv('~/Downloads/current.csv')# Clean the DataFrame by removing the row with transformation codesdf_cleaned = df.drop(index=0)df_cleaned.reset_index(drop=True, inplace=True)df_cleaned['sasdate'] = pd.to_datetime(df_cleaned['sasdate'], format='%m/%d/%Y')df_cleaned
The transformation codes map variables to the transformations we must apply to each variable to render them (approximately) stationary. The data frame transformation_codes has the variable’s name (Series) and its transformation (Transformation_Code). There are six possible transformations (\(x_t\) denotes the variable to which the transformation is to be applied):
We can apply these transformations using the following code:
import numpy as np# Function to apply transformations based on the transformation codedef apply_transformation(series, code):if code ==1:# No transformationreturn serieselif code ==2:# First differencereturn series.diff()elif code ==3:# Second differencereturn series.diff().diff()elif code ==4:# Logreturn np.log(series)elif code ==5:# First difference of logreturn np.log(series).diff()elif code ==6:# Second difference of logreturn np.log(series).diff().diff()elif code ==7:# Delta (x_t/x_{t-1} - 1)return series.pct_change()else:raiseValueError("Invalid transformation code")# Applying the transformations to each column in df_cleaned based on transformation_codesfor series_name, code in transformation_codes.values: df_cleaned[series_name] = apply_transformation(df_cleaned[series_name].astype(float), float(code))1df_cleaned = df_cleaned[2:]2df_cleaned.reset_index(drop=True, inplace=True)df_cleaned.head()
1
Since some transformations induce missing values, we drop the first two observations of the dataset
2
We reset the index so that the first observation of the dataset has index 0
sasdate
RPI
W875RX1
DPCERA3M086SBEA
CMRMTSPLx
RETAILx
INDPRO
IPFPNSS
IPFINAL
IPCONGD
...
DNDGRG3M086SBEA
DSERRG3M086SBEA
CES0600000008
CES2000000008
CES3000000008
UMCSENTx
DTCOLNVHFNM
DTCTHFNM
INVEST
VIXCLSx
0
1959-03-01
0.006457
0.007325
0.009404
-0.003374
0.008321
0.014306
0.006035
0.004894
0.000000
...
-0.001148
0.000292
-0.000022
-0.008147
0.004819
NaN
0.004929
0.004138
-0.014792
NaN
1
1959-04-01
0.006510
0.007029
-0.003622
0.019915
0.000616
0.021075
0.014338
0.014545
0.015650
...
0.001312
0.001760
-0.000022
0.012203
-0.004890
NaN
0.012134
0.006734
0.024929
NaN
2
1959-05-01
0.005796
0.006618
0.012043
0.006839
0.007803
0.014955
0.008270
0.009582
0.004770
...
-0.001695
-0.001867
-0.000021
-0.004090
-0.004819
NaN
0.002828
0.002020
-0.015342
NaN
3
1959-06-01
0.003068
0.003012
0.003642
-0.000097
0.009064
0.001141
0.007034
0.007128
-0.004767
...
0.003334
0.001946
-0.004619
0.003992
0.004796
NaN
0.009726
0.009007
-0.012252
NaN
4
1959-07-01
-0.000580
-0.000762
-0.003386
0.012155
-0.000330
-0.024240
0.001168
0.008249
0.013054
...
-0.001204
-0.000013
0.000000
-0.004040
-0.004796
NaN
-0.004631
-0.001000
0.029341
NaN
5 rows × 128 columns
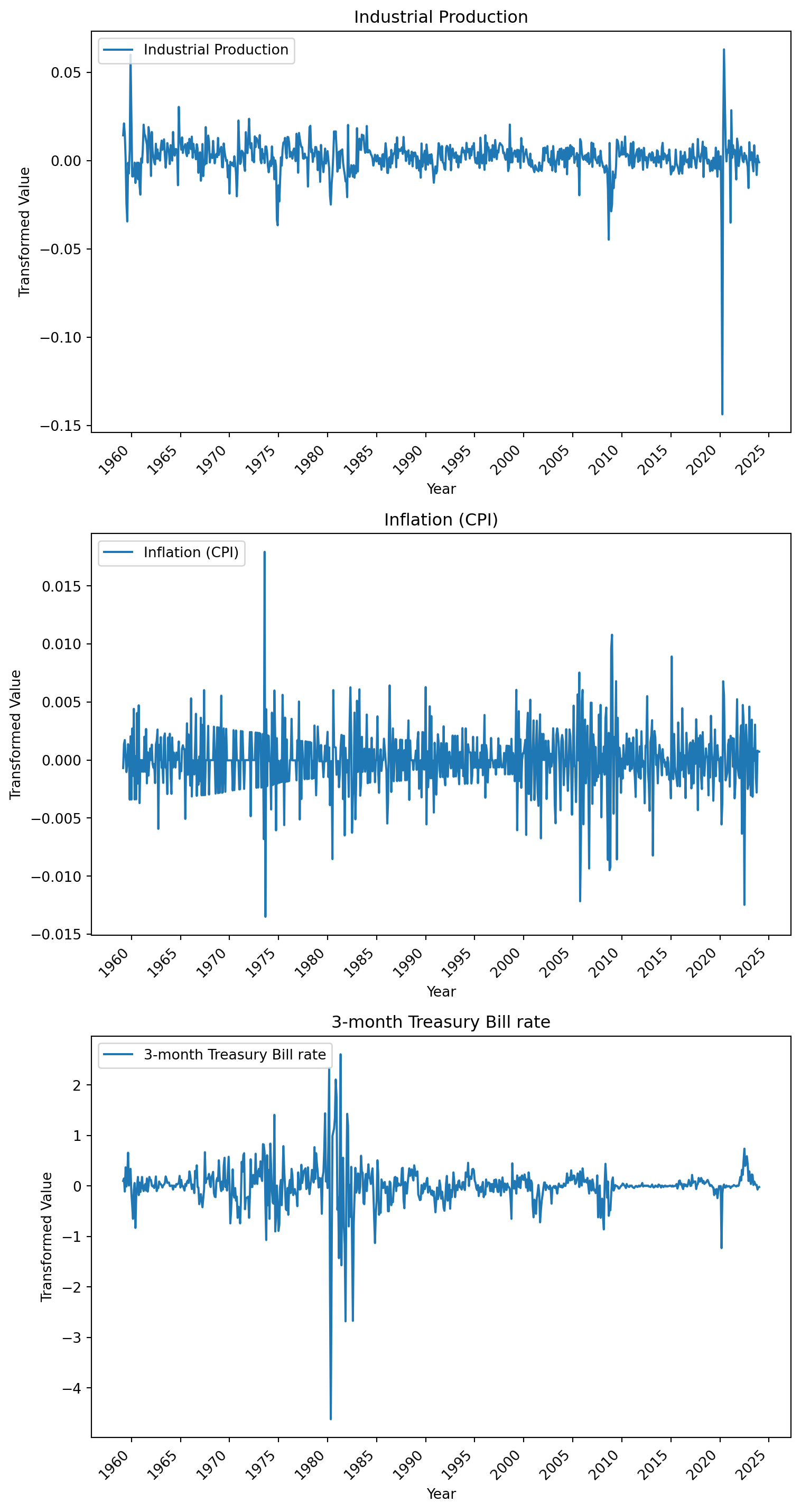
1import matplotlib.pyplot as pltimport matplotlib.dates as mdates2series_to_plot = ['INDPRO', 'CPIAUCSL', 'TB3MS']series_names = ['Industrial Production','Inflation (CPI)','3-month Treasury Bill rate']# Create a figure and a grid of subplots3fig, axs = plt.subplots(len(series_to_plot), 1, figsize=(8, 15))# Iterate over the selected series and plot each onefor ax, series_name, plot_title inzip(axs, series_to_plot, series_names):4if series_name in df_cleaned.columns:5 dates = pd.to_datetime(df_cleaned['sasdate'], format='%m/%d/%Y')6 ax.plot(dates, df_cleaned[series_name], label=plot_title)7 ax.xaxis.set_major_locator(mdates.YearLocator(base=5)) ax.xaxis.set_major_formatter(mdates.DateFormatter('%Y'))8 ax.set_title(plot_title)9 ax.set_xlabel('Year') ax.set_ylabel('Transformed Value')10 ax.legend(loc='upper left')11 plt.setp(ax.xaxis.get_majorticklabels(), rotation=45, ha='right')else: ax.set_visible(False) # Hide plots for which the data is not available12plt.tight_layout()13plt.show()
1
We use library matplotlib to plot
2
We consider three series (INDPRO, CPIAUCSL, TB3MS) and assign them human-readable names (“Industrial Production”, “Inflation (CPI)”, “3-month Treasury Bill rate.”).
3
We create a figure with three (len(series_to_plot)) subplots arranged vertically. The figure size is 8x15 inches.
4
We check if the series exists in each series df_cleaned DataFrame columns.
5
We convert the sasdate column to datetime format (not necessary, since sasdate was converter earlier)
6
We plot each series against the sasdate on the corresponding subplot, labeling the plot with its human-readable name.
7
We format the x-axis to display ticks and label the x-axis with dates taken every five years.
8
Each subplot is titled with the name of the economic indicator.
9
We label the x-axis “Year,” and the y-axis “Transformed Value,” to indicate that the data was transformed before plotting.
10
A legend is added to the upper left of each subplot for clarity.
11
We rotate the x-axis labels by 45 degrees to prevent overlap and improve legibility.
12
plt.tight_layout() automatically adjusts subplot parameters to give specified padding and avoid overlap.
13
plt.show() displays the figure with its subplots.
Forecasting in Time Series
Forecasting in time series analysis involves using historical data to predict future values. The objective is to model the conditional expectation of a time series based on past observations.
Direct Forecasts
Direct forecasting involves modeling the target variable directly at the desired forecast horizon. Unlike iterative approaches, which forecast one step ahead and then use those forecasts as inputs for subsequent steps, direct forecasting directly models the relationship between past observations and future value.
ARX Models
Autoregressive Moving with predictors (ARX) models are a class of univariate time series models that extend ARMA models by incorporating exogenous (independent) variables. These models are formulated as follows:
\(X_{t,j}\): Predictors (variable \(j=1,\ldots,k\) at time \(t\)).
\(p\) number of lags of the target and the predictors.1
\(\phi_i\), \(i=0,\dots,p\), and \(\theta_{j,s}\), \(j=1,\dots,k\), \(s=1,\ldots,r\): Parameters of the model.
\(\epsilon_{t+h}\): error term.
For instance, to predict Industrial Prediction using as predictor inflation and the 3-month t-bill, the target variable is INDPRO, and the predictors are CPIAUSL and TB3MS. Notice that the target and the predictors are the transformed variables. Thus, if we use INDPRO as the target, we are predicting the log-difference of industrial production, which is a good approximation for its month-to-month percentage change.
By convention, the data ranges from \(t=1,\ldots,T\), where \(T\) is the last period, we have data (for the df_cleaned dataset, \(T\) corresponds to January 2024).
Forecasting with ARX
Suppose that we know the parameters of the model for the moment. To obtain a forecast for \(Y_{T+h}\), the \(h\)-step ahead forecast, we calculate \[
\begin{aligned}
\hat{Y}_{T+h} &= \alpha + \phi_0 Y_T + \phi_1 Y_{T-1} + \dots + \phi_p Y_{T-p} \\
&\,\,\quad \quad + \theta_{0,1} X_{T,1} + \theta_{1,1} X_{T-1,1} + \dots + \theta_{p,1} X_{T-p,1} \\
&\,\,\quad \quad + \dots + \theta_{0,k} X_{T,k} + \dots + \theta_{p,k} X_{T-p,k}\\
&= \alpha + \sum_{i=0}^p \phi_i Y_{T-i} + \sum_{j=1}^k\sum_{s=0}^p \theta_{s,j} X_{T-s,j}
\end{aligned}
\]
While this is conceptually easy, implementing the steps needed to calculate the forecast is insidious, and care must be taken to ensure we are calculating the correct forecast.
To start, it is convenient to rewrite the model in Equation 1 as a linear model \[
\mathbf{y} = \mathbf{X}\boldsymbol{\beta} + \mathbf{u},
\] where \(\boldsymbol{\beta}\) is the vector (of size \(1+(1+p)(1+k)\)) \[
\boldsymbol{\beta}=\begin{pmatrix}\alpha\\
\phi_{0}\\
\vdots\\
\phi_{p}\\
\theta_{0,1}\\
\vdots\\
\theta_{p,1}\\
\vdots\\
\theta_{1,k}\\
\vdots\\
\theta_{p,k}
\end{pmatrix},
\]\(\mathbf{y}\) and \(\mathbf{X}\) are respectively given by \[
\mathbf{y} = \begin{pmatrix}
y_{p+h+1} \\
y_{p+h+2}\\
\vdots \\
y_{T}
\end{pmatrix}
\] and \[
\mathbf{X} = \begin{pmatrix}1 & Y_{p+1} & Y_{p} & \cdots & Y_{1} & X_{p+1,1} & X_{p,1} & \cdots & X_{1,1} & X_{p+1,k} & X_{p,k} & \cdots & X_{1,k}\\
\vdots & \vdots & \vdots & & \vdots & \vdots & \vdots & & \vdots & \vdots & \vdots & & \vdots\\
1 & Y_{T-h-1} & Y_{T-h-2} & \cdots & Y_{T-h-p-1} & X_{T-h-1,1} & X_{T-h-2,1} & \cdots & X_{T-h-p-1,1} & X_{T-h-1,k} & X_{T-h-2,k} & \cdots & X_{T-h-p-1,k}\\
1 & Y_{T-h} & Y_{T-h-1} & \cdots & Y_{T-h-p} & X_{T-h,1} & X_{T-h-1,1} & \cdots & X_{T-h-p,1} & X_{T-h,k} & X_{T-h-1,k} & & X_{T-h-p,k}
\end{pmatrix}.
\] The size of \(\mathbf{X}\) is \((T-p-h)\times 1+(1+k)(1+p)\) and that of \(\mathbf{y}\) is \(T-h-p\).
The matrix \(\mathbf{X}\) can be obtained in the following way:
Yraw = df_cleaned['INDPRO']Xraw = df_cleaned[['CPIAUCSL', 'TB3MS']]num_lags =4## this is pnum_leads =1## this is hX = pd.DataFrame()## Add the lagged values of Ycol ='INDPRO'for lag inrange(0,num_lags+1):# Shift each column in the DataFrame and name it with a lag suffix X[f'{col}_lag{lag}'] = Yraw.shift(lag)for col in Xraw.columns:for lag inrange(0,num_lags+1):# Shift each column in the DataFrame and name it with a lag suffix X[f'{col}_lag{lag}'] = Xraw[col].shift(lag)## Add a column on ones (for the intercept)X.insert(0, 'Ones', np.ones(len(X)))## X is now a DataFrameX.head()
Ones
INDPRO_lag0
INDPRO_lag1
INDPRO_lag2
INDPRO_lag3
INDPRO_lag4
CPIAUCSL_lag0
CPIAUCSL_lag1
CPIAUCSL_lag2
CPIAUCSL_lag3
CPIAUCSL_lag4
TB3MS_lag0
TB3MS_lag1
TB3MS_lag2
TB3MS_lag3
TB3MS_lag4
0
1.0
0.014306
NaN
NaN
NaN
NaN
-0.000690
NaN
NaN
NaN
NaN
0.10
NaN
NaN
NaN
NaN
1
1.0
0.021075
0.014306
NaN
NaN
NaN
0.001380
-0.000690
NaN
NaN
NaN
0.15
0.10
NaN
NaN
NaN
2
1.0
0.014955
0.021075
0.014306
NaN
NaN
0.001723
0.001380
-0.000690
NaN
NaN
-0.11
0.15
0.10
NaN
NaN
3
1.0
0.001141
0.014955
0.021075
0.014306
NaN
0.000339
0.001723
0.001380
-0.00069
NaN
0.37
-0.11
0.15
0.10
NaN
4
1.0
-0.024240
0.001141
0.014955
0.021075
0.014306
-0.001034
0.000339
0.001723
0.00138
-0.00069
-0.01
0.37
-0.11
0.15
0.1
Note that the first \(p=\)4 rows of X have missing values.
The vector \(\mathbf{y}\) can be similarly created as
The variable y has missing values in the last h positions (it is not possible to lead the target beyond \(T\)).
Notice also that we must keep the last row of X for constructing the forecast.
Now we create two numpy arrays with the missing values stripped:
## Save last row of X (converted to numpy)X_T = X.iloc[-1:].values## Subset getting only rows of X and y from p+1 to h-1## and convert to numpy arrayy = y.iloc[num_lags:-num_leads].valuesX = X.iloc[num_lags:-num_leads].values
Now, we have to estimate the parameters and obtain the forecast.
Estimation
The parameters of the model can be estimated by OLS (the OLS estimates the coefficient of the linear projection of \(Y_{t+h}\) on its lags and the lags of \(X_t\)).
The OLS estimator of \(\boldsymbol{\beta}\) is \[
\hat{\boldsymbol{\beta}} = (X'X)^{-1}X'Y.
\]
While this is the formula used to describe the OLS estimator, from a computational poijnt of view is much better to define the estimator as the solution of the set of linear equations: \[
(X'X)\boldsymbol{\beta} = X'Y
\]
The function solve can be used to solve this linear system of equation.
from numpy.linalg import solve# Solving for the OLS estimator beta: (X'X)^{-1} X'Ybeta_ols = solve(X.T @ X, X.T @ y)## Produce the One step ahead forecast## % change month-to-month INDPROforecast = X_T@beta_ols*100forecast
array([0.08445815])
The variable forecast contains now the one-step ahead (\(h=1\) forecast) of INDPRO. Since INDPRO has been transformed in logarithmic differences, we are forecasting the percentage change (and multiplying by 100 gives the forecast in percentage points).
To obtain the \(h\)-step ahead forecast, we must repeat all the above steps using a different h.
Forecasting Exercise
How good is the forecast that the model is producing? One thing we could do to assess the forecast’s quality is to wait for the new data on industrial production and see how big the forecasting error is. However, this evaluation would not be appropriate because we need to evaluate the forecast as if it were repeatedly used to forecast future values of the target variables. To properly assess the model and its ability to forecast INDPRO, we must keep producing forecasts and calculating the errors as new data arrive. This procedure would take time as we must wait for many months to have a series of errors that is large enough.
A different approach is to do what is called a Real-time evaluation. A Real-time evaluation procedure consists of putting ourselves in the shoes of a forecaster who has been using the forecasting model for a long time.
In practice, that is what are the steps to follow to do a Real-time evaluation of the model:
Set \(T\) such that the last observation of df coincides with December 1999;
Estimate the model using the data up to \(T\)
Produce \(\hat{Y}_{T+1}, \hat{Y}_{T+2}, \dots, \hat{Y}_{T+H}\)
Since we have the actual data for January, February, …, we can calculate the forecasting errors of our model \[
\hat{e}_{T+h} = \hat{Y}_{T+h} - Y_{T+h}, \,\, h = 1,\ldots, H.
\]
Set \(T = T+1\) and do all the steps above.
The process results are a series of forecasting errors we can evaluate using several metrics. The most commonly used is the MSFE, which is defined as \[
MSFE_h = \frac{1}{J}\sum_{j=1}^J \hat{e}_{T+j+h}^2,
\] where \(J\) is the number of errors we collected through our real-time evaluation.
This assignment asks you to perform a real-time evaluation assessment of our simple forecasting model and calculate the MSFE for steps \(h=1,4,8\).
As a bonus, we can evaluate different models and see how they perform differently. For instance, you might consider different numbers of lags and/or different variables in the model.
Hint
A sensible way to structure the code for real-time evaluation is to use several functions. For instance, you can define a function that calculates the forecast given the DataFrame.
def calculate_forecast(df_cleaned, p =4, H = [1,4,8], end_date ='12/1/1999',target ='INDPRO', xvars = ['CPIAUCSL', 'TB3MS']):## Subset df_cleaned to use only data up to end_date rt_df = df_cleaned[df_cleaned['sasdate'] <= pd.Timestamp(end_date)]## Get the actual values of target at different steps ahead Y_actual = []for h in H: os = pd.Timestamp(end_date) + pd.DateOffset(months=h) Y_actual.append(df_cleaned[df_cleaned['sasdate'] == os][target]*100)## Now Y contains the true values at T+H (multiplying * 100) Yraw = rt_df[target] Xraw = rt_df[xvars] X = pd.DataFrame()## Add the lagged values of Yfor lag inrange(0,p):# Shift each column in the DataFrame and name it with a lag suffix X[f'{target}_lag{lag}'] = Yraw.shift(lag)for col in Xraw.columns:for lag inrange(0,p): X[f'{col}_lag{lag}'] = Xraw[col].shift(lag)## Add a column on ones (for the intercept) X.insert(0, 'Ones', np.ones(len(X)))## Save last row of X (converted to numpy) X_T = X.iloc[-1:].values## While the X will be the same, Y needs to be leaded differently Yhat = []for h in H: y_h = Yraw.shift(-h)## Subset getting only rows of X and y from p+1 to h-1 y = y_h.iloc[p:-h].values X_ = X.iloc[p:-h].values# Solving for the OLS estimator beta: (X'X)^{-1} X'Y beta_ols = solve(X_.T @ X_, X_.T @ y)## Produce the One step ahead forecast## % change month-to-month INDPRO Yhat.append(X_T@beta_ols*100)## Now calculate the forecasting error and returnreturn np.array(Y_actual) - np.array(Yhat)
With this function, you can calculate real-time errors by looping over the end_date to ensure you end the loop at the right time.
t0 = pd.Timestamp('12/1/1999')e = []T = []for j inrange(0, 10): t0 = t0 + pd.DateOffset(months=1)print(f'Using data up to {t0}') ehat = calculate_forecast(df_cleaned, p =4, H = [1,4,8], end_date = t0) e.append(ehat.flatten()) T.append(t0)## Create a pandas DataFrame from the listedf = pd.DataFrame(e)## Calculate the RMSFE, that is, the square root of the MSFEnp.sqrt(edf.apply(np.square).mean())
Using data up to 2000-01-01 00:00:00
Using data up to 2000-02-01 00:00:00
Using data up to 2000-03-01 00:00:00
Using data up to 2000-04-01 00:00:00
Using data up to 2000-05-01 00:00:00
Using data up to 2000-06-01 00:00:00
Using data up to 2000-07-01 00:00:00
Using data up to 2000-08-01 00:00:00
Using data up to 2000-09-01 00:00:00
Using data up to 2000-10-01 00:00:00
0 0.337110
1 0.512690
2 0.624035
dtype: float64
You may change the function calculate_forecast to output also the actual data end the forecast, so you can, for instance, construct a plot.
The comptools_ass1.qmd is this file (in quarto format). The repository also contains the pdf and the html version of this file.
The other files, assignment1_julia.jl, assignment1_julia.py, and assignment1_julia.py, are the starter kit of the code you have to write in Julia, R, and Python. You can use them to start your work.
Using Visual Studio Code
Unless you are familiar with the command line and you are using Linux or MacOS, the best way to interact with github is through Visual Studio Code. Instructions on how to install Visual Studio Code on Windows are here. For MacOS the instructions are here.
Visual Studio Code has an extension system. The extensions extend VSCode adding features that simplify writing and interacting with code.
There are many other extensions that you might find useful. For those, google is your friend.
Cloning the repository
Cloning a repository from GitHub into Visual Studio Code (VSCode) allows you to work on projects directly from your local machine. Here’s a detailed step-by-step guide on how to clone the repository https://github.com/uniroma/comptools-assignments into VSCode:
Open Visual Studio Code
Start by opening Visual Studio Code on your computer.
Access the Command Palette
With VSCode open, access the Command Palette by pressing Ctrl+Shift+P on Windows/Linux or Cmd+Shift+P on macOS. This is where you can quickly access various commands in VSCode.
Clone Repository
In the Command Palette, type “Git: Clone” and select the option Git: Clone from the list that appears. This action will prompt VSCode to clone a repository.
Enter the Repository URL
A text box asking for the repository URL will appear at the top of the VSCode window. Enter https://github.com/uniroma/comptools-assignments and press Enter. (This is the URL of the assignment 1 repository).
Choose a Directory
Next, VSCode will ask you to select a directory where you want to clone the repository. Navigate through your file system and choose a directory that will be the local storage place for the repository. The directory should exist. Create it if it doesn’t. Once selected, the cloning process will start.
Open the Cloned Repository
After the repository has been successfully cloned, a notification will pop up in the bottom right corner of VSCode with the option to Open Repository. Click on it. If you missed the notification, you can navigate to the directory where you cloned the repository and open it manually from within VSCode by going to File > Open Folder.
Start Working
Now that the repository is cloned and opened in VSCode, you can start working on the project. You can edit files, commit changes, and manage branches directly from VSCode.
Tip
Ensure you have Git installed on your computer to use the Git features in VSCode. If you do not have Git installed, you can download it from the official Git website. Instructions to install Git.
If you are working with GitHub repositories frequently, consider authenticating with GitHub in VSCode to streamline your workflow. This can be done through the Command Palette by finding the GitHub: Sign in command.
Make changes and commit them to the repository
Make Your Changes
Open the repository you have cloned in VSCode.
Navigate to the file(s) you wish to change within the VSCode Explorer pane.
Make the necessary modifications or additions to the file(s). These changes can be anything from fixing a bug to adding new features.
Review Your Changes
After making changes, you can see which files have been modified by looking at the Source Control panel. You can access this panel by clicking on the Source Control icon (it looks like a branch or a fork) on the sidebar or by pressing Ctrl+Shift+G (Windows/Linux) or Cmd+Shift+G (macOS) and searching for Show control panel.
Modified files are listed within the Source Control panel. Click on a file to view the changes (differences) between your working version and the last commit. Lines added are highlighted in green, and lines removed are highlighted in red.
Stage Your Changes
Before committing, you need to stage your changes. Staging is like preparing and reviewing exactly what changes you will commit to without making the commit final.
You can stage changes by right-clicking on a modified file in the Source Control panel and selecting Stage Changes. Alternatively, you can stage all changes at once by clicking the + icon next to the “Changes” header.
Commit Your Changes
After staging your changes, commit them to the repository. To do this, type a commit message in the message box at the top of the Source Control panel. This message should briefly describe the changes you’ve made.
Press Ctrl+Enter (Windows/Linux) or Cmd+Enter (macOS) to commit the staged changes (search for Git: Commit). Alternatively, you can click the checkmark icon (Commit) at the top of the Source Control panel.
Before committing, you should enter a commit message that briefly describes the changes that you have made. Commit messages are essential for making the project’s history understandable for yourself and the other collaborators.
Push Your Changes
If you’re working with a remote repository (like one hosted on GitHub), you must push your commits to update the remote repository with your local changes.
You can push changes by clicking on the three dots (...) menu in the Source Control panel, navigating to Push and selecting it. If you’re using Git in VSCode for the first time, you might be prompted to enter your GitHub credentials or authenticate in another way.
Tip
It’s a good practice to pull changes from the remote repository before starting your work session (to ensure you’re working with the latest version) and before pushing your changes (to ensure no conflicts). You can pull changes by clicking on the three dots (...) menu in the Source Control panel and selecting Pull.
The following video explores in more detail how to use git in VSCode.
Footnotes
Theoretically, the number of lags for the target variables and the predictors could be different. Here, we consider the simpler case in which both are equal.↩︎